Generate Embeddings
This workflow uses pre-trained models to generate embeddings across some common modalities.
Images
This workflow allows you to add embeddings for images in ApertureDB using a pre-trained model. This means that you can use the embeddings to search for similar images, or to classify images based on the embeddings. This provides an easy way to add embeddings to your images, and to see how they can be used with real data.
PDF documents
The workflow will also allow you to add embeddings for PDF documents. This works slightly differently from images because, in addition to extracting text from the PDF, the full text is then segmented into shorter texts. This allows you to find relevant sections in the PDF document that are similar to some input text.
Video content
The workflow will generate the embeddings from some of the frames from a video. The information will be used to add clips to the video, and also associate embeddings to the video itself. This enables the user to be able to query the video, or specifically to the clip in the video where the embedding is extraced from.
Creating the workflow
![[object Object]](/assets/images/configure_embeddings_extraction-7fbd9f60a637bf0af52cfd072e1ca244.png)
- Select which CLIP embeddings model you wish to use.
- Select whether you want to generate embeddings for images, PDFs, or videos. You can pick as many as you want, but you must choose at least one.
- Click the blue button at the bottom.
See the results
If you go to the "My Instances" page and click on "Connect" for the instance you used, you will see an option to go to the Web UI for your instance. You will see the number of descriptors in the database increase as the workflow runs. Click on the refresh button to update the count.
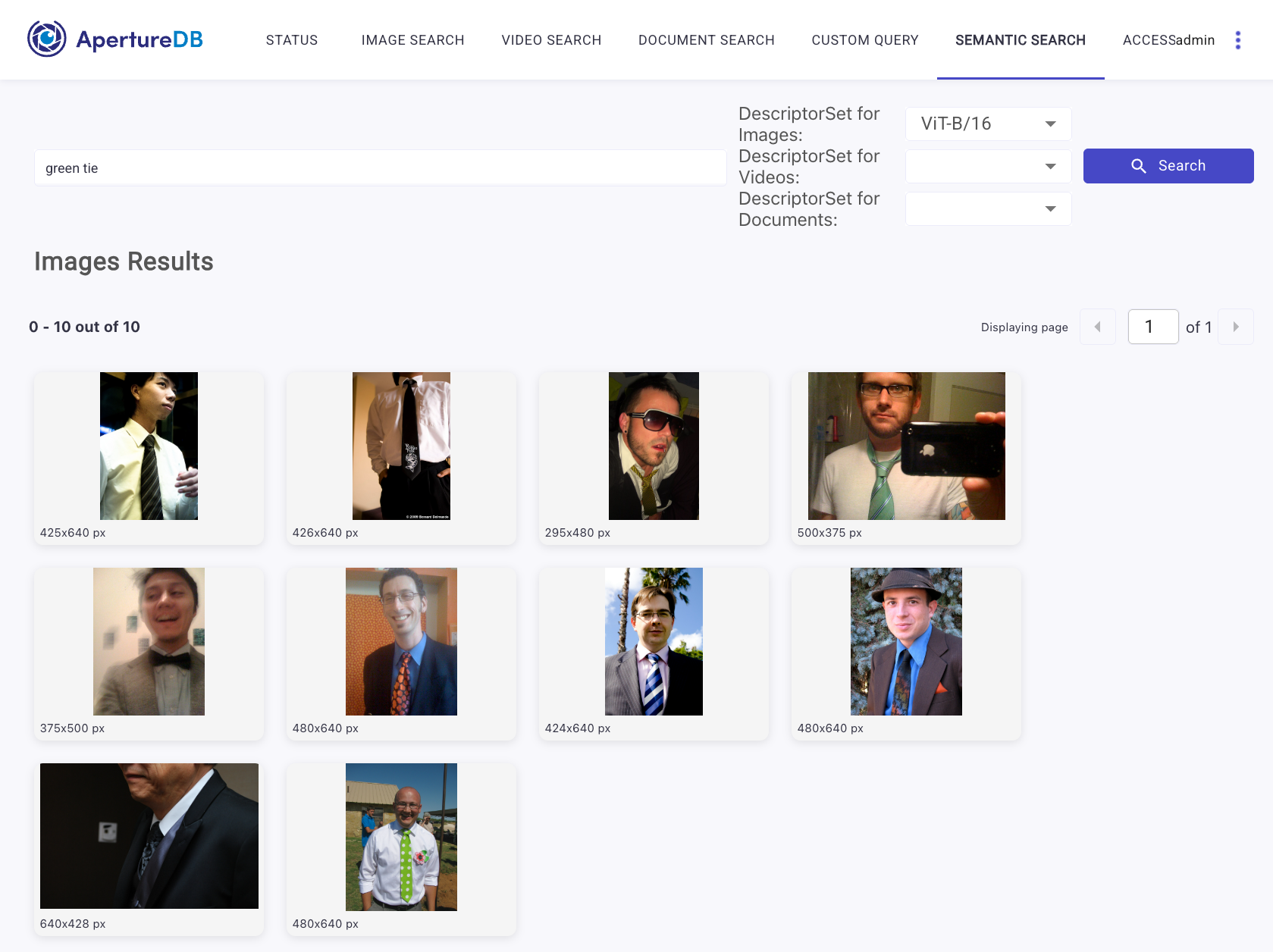
You can also use your embeddings via the "Semantic Search" feature. Click on the "SEMANTIC SEARCH" tab in the WebUI, enter a text query, double-check the selected descriptor set, and press "Search". You should see images that are related to your query.