Why ApertureDB?
Multimodal data (images, videos, documents) is rich in business and consumer information. Advancements in data science, machine learning (ML), or multimodal AI in general, are making this information more and more accessible. Across many different domains, people are collecting large and varied corpora of multimodal data and developing ever more powerful models to gain insight from them. While the tools and techniques for analyzing such datasets are improving significantly, the tools for managing this data have remained largely unchanged.
Across many different analytics applications, some [common complex and time consuming tasks](https://medium.com/aperturedata/building-a-specialized-database-for-analytics-\ on-images-and-videos-e5f713718abe?source=friends_link&sk=5749c9dc3ed23005807455bfc82ceefd>) include:
- Managing different modalities of data
- Searching and visualizing complex data at scale
- Managing datasets and annotations
- Debugging models in the context of their training data
- Automating the retraining of models on newer and varied data
- Inferencing on large sets of production data
Status Quo: Manually Integrated Solution
Most analytics applications involve a variety of data modalities such as pixel data (images, videos), metadata (tags, annotations), and feature vectors (embeddings or descriptors). These data modalities have widely different characteristics and usage patterns.
Today, for such applications, users have to choose between using a general purpose data solution that may not be optimal for all modalities, or using multiple point solutions that then have to be separately integrated and maintained.
Figure 1 shows an example of how to assemble a solution using current tools and databases in order to transform this complex input data into useful outputs like recommendations, models to deploy, or query results.
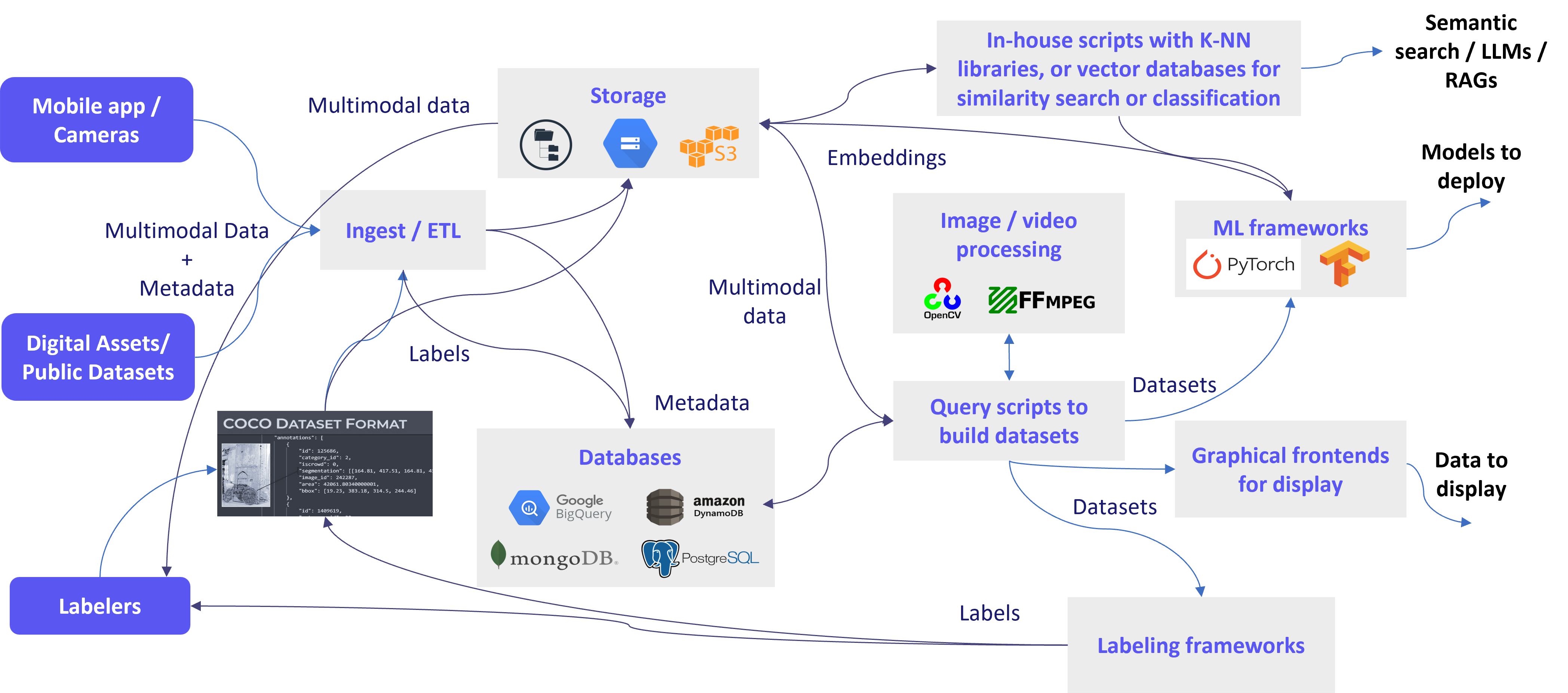
For instance, the starting point often is a stream or data dump consisting of different types of data like images, videos and application metadata. Frequently files gets stored in cloud buckets or folders on-premises and metadata is directed to some choice of database(s).
Very often ML workflows require labeled data for training models. That means either manual or automatic labelers need access to these datasets, and in return provide annotations in some format. These annotations also need to be ingested. They land either in cloud buckets or are sometimes transformed into metadata in database to allow label-based searches later.
After that, users create their own custom integrations (do-it-yourself or DIY) to assemble their data into a coherent dataset for use by an ML framework for training / inference or a frontend for display. Sometimes these integrations can require preprocessing or augmentation to the original data for various reasons like ease of display or requirements of a neural network. This means dealing with computer vision libraries like OpenCV or ffmpeg which can pose their own integration challenges.
Users implementing these analytics applications commonly have to address the indexing of high-dimensional embeddings and proximity search, such as systems for recommendations or to find similar items without needing keywords or labels. This typically requires yet another tool, like a vector database.
What that ends up looking like is a complex, bespoke system that is brittle and painful to install, maintain, and reuse. This gets worse with multiple use cases expand and applications and data continue to evolve.
Missing Piece: Purpose-built Database for Multimodal AI
A database that not only understands the complexity of multimodal data management but also understands analytics requirements is what can address these challenges and make it easy for teams to adopt and deploy in production. Further, a tight internal integration between disparate data modalities with an understanding of their semantic usage allows for significant performance optimization. That’s what we offer with ApertureDB!
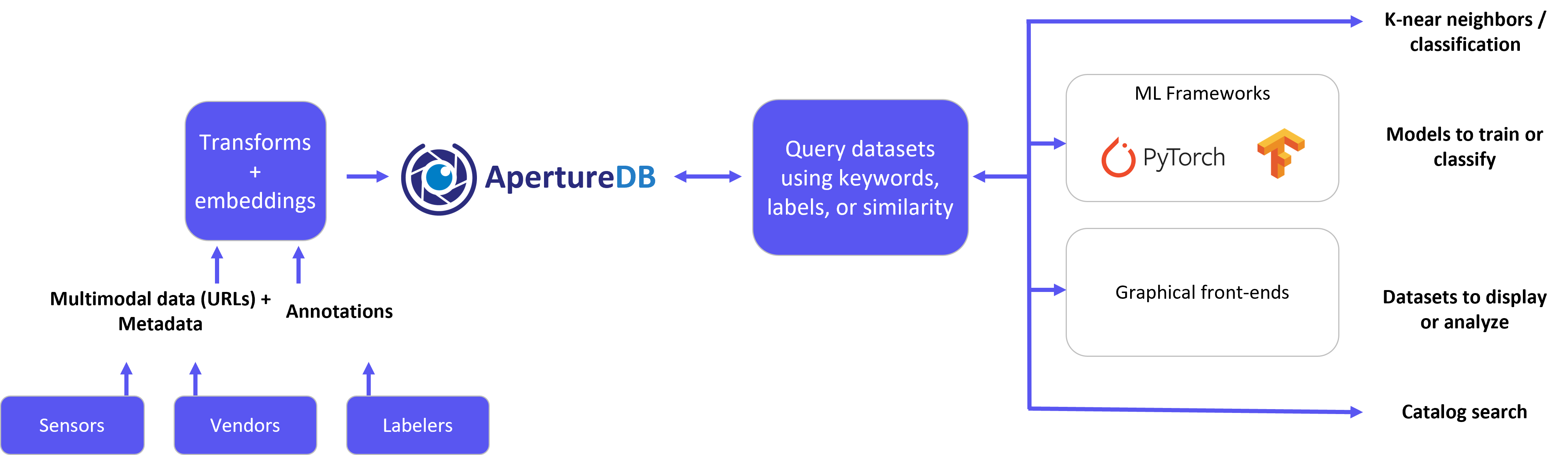
The way we have designed and implemented ApertureDB has clear advantages compared to any DIY solution, even those composed with the best point solutions out there. Data scientists using ApertureDB can create their datasets potentially 35X faster, depending on the query complexity (VLDB'21). With our unified design and near data preprocessing, data science and engineering teams are no longer forced to manually integrate disparate data, and we see sizeable reduction in network transfers. ApertureDB continues to scale with data and use cases.
Basically, ApertureDB is a very high-performance and scalable database because of its architecture and implementation, so your data pipelines are never the bottleneck! Analytics teams get what they need from their data layer without worrying about building it or maintaining it, even at enterprise scale.