Quick Start
![]()
![]()
In this notebook:
- Connect to ApertureDB
- Load the Cookbook dataset
- Run queries — metadata filters, graph traversal, and vector search
Connect to ApertureDB
Option A: ApertureDB Cloud (recommended)
Sign up for a free 30-day trial. Get your key from Connect > Generate API Key, add it to a .env file in this directory:
APERTUREDB_KEY=your_key_here
Option B: Community Edition (local Docker)
Run this in a terminal before starting the notebook:
docker run -d --name aperturedb \\
-p 55555:55555 -e ADB_MASTER_KEY=admin -e ADB_FORCE_SSL=false \\
aperturedata/aperturedb-community
%pip install --upgrade --quiet aperturedb python-dotenv
# Option A: ApertureDB Cloud
from dotenv import load_dotenv
load_dotenv() # loads APERTUREDB_KEY from .env into the environment
True
# Option B: Community Edition (local Docker)
# !adb config create localdb --active \\
# --host localhost --port 55555 \\
# --username admin --password admin \\
# --no-use-ssl --no-interactive
Connect and Verify
Run GetStatus to confirm your connection is working.
from aperturedb.Utils import Utils
from aperturedb.CommonLibrary import create_connector
# Create the connector for ApertureDB
client = create_connector()
# Use the connector to create a Utils object and print the summary
utils = Utils(client)
utils.summary()
Load the Cookbook Dataset
The Cookbook dataset contains 20 dishes with photos, descriptions, and ingredients — built to demonstrate ApertureDB capabilities.
! wget https://github.com/aperture-data/Cookbook/raw/refs/heads/main/scripts/load_cookbook_data.sh
! bash load_cookbook_data.sh
from aperturedb.cli.ingest import from_csv, TransformerType, IngestType
from_csv(
filepath="data/dishes.adb.csv",
ingest_type=IngestType.IMAGE,
transformer=[
TransformerType.clip_pytorch_embeddings,
TransformerType.image_properties,
TransformerType.common_properties]
)
from_csv(
filepath="data/ingredients.adb.csv",
ingest_type=IngestType.ENTITY,
)
from_csv(
filepath="data/dish_ingredients.adb.csv",
ingest_type=IngestType.CONNECTION,
)
100%|███████████████████████████████████████| 335M/335M [00:06<00:00, 53.2MiB/s]
0%| | 0.00/107M [00:00<?, ?B/s]
sample_count 30
``````output
Progress: 100%|██████████| 30.0/30.0 [00:19<00:00, 1.58items/s]
``````output
============ ApertureDB Loader Stats ============
Total time (s): 19.024478673934937
Total queries executed: 30
Avg Query time (s): 0.270937975247701
Query time std: 0.20982933835044162
Avg Query Throughput (q/s): 3.690881645829695
Overall insertion throughput (element/s): 1.5769157470318704
Total inserted elements: 30
Total successful commands: 60
=================================================
sample_count 65
``````output
Progress: 100%|██████████| 65.0/65.0 [00:09<00:00, 7.21items/s]
``````output
============ ApertureDB Loader Stats ============
Total time (s): 9.01276445388794
Total queries executed: 65
Avg Query time (s): 0.12738604545593263
Query time std: 0.12897449230058589
Avg Query Throughput (q/s): 7.850153416890044
Overall insertion throughput (element/s): 7.2119936488476855
Total inserted elements: 65
Total successful commands: 65
=================================================
sample_count 69
``````output
Progress: 100%|██████████| 69.0/69.0 [00:09<00:00, 7.66items/s]
``````output
============ ApertureDB Loader Stats ============
Total time (s): 9.013163328170776
Total queries executed: 69
Avg Query time (s): 0.12440769223199374
Query time std: 0.12473818331751528
Avg Query Throughput (q/s): 8.038088176535048
Overall insertion throughput (element/s): 7.655469837580716
Total inserted elements: 69
Total successful commands: 207
=================================================
``````output
Run Queries
a) Find images of dishes from Scottish Cuisine
For this simple query, we are able to use an object wrapper class.
from aperturedb.Images import Images
from aperturedb.Constraints import Constraints
# Create an Images wrapper object
images = Images(client)
# Search
images.search(
constraints=Constraints().equal("cuisine", "Scottish"),
limit=3,
)
# display result
images.display()



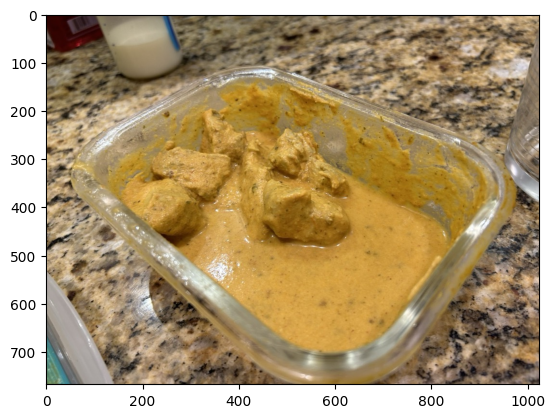
b) Find images and information of dishes with butter and chicken in them
from aperturedb.CommonLibrary import create_connector, execute_query
from aperturedb.NotebookHelpers import display
query = [
{ # Find an ingredient with the name "butter"
"FindEntity": {
"with_class": "Ingredient",
"constraints": {
"name": [
"==",
"butter"
]
},
"_ref": 1, # forward reference
}
},
{ # Find an ingredient with the name "chicken"
"FindEntity": {
"with_class": "Ingredient",
"constraints": {
"name": [
"==",
"chicken"
]
},
"_ref": 2 # forward reference
}
},
{ # Find an image connected to both ingredients
"FindImage": {
"blobs": True,
"is_connected_to": {
"all": [ # Must be connected to all ingredients
{
"ref": 1, # backward reference
},
{
"ref": 2, # backward reference
}
]
},
"results": {
"limit": 5, # Maximum of five results
"all_properties": True # Return all properties
}
}
}
]
client = create_connector()
result, response, blobs = execute_query(client, query, [])
# Print the response
print(response)
# Check if the query was successful
if result == 0:
display(blobs)
[{'FindEntity': {'returned': 0, 'status': 0}}, {'FindEntity': {'returned': 0, 'status': 0}}, {'FindImage': {'blobs_start': 0, 'entities': [{'Recipe URL': 'https://www.indianhealthyrecipes.com/butter-chicken/', '_blob_index': 0, '_uniqueid': '15.3.484460', 'adb_data_source': 'IngestType.IMAGE.dishes.adb.csv', 'adb_image_height': 768, 'adb_image_id': '4', 'adb_image_sha256': 'a3b41c925f1d51003ef7dd924999eed0d04b31752a9dacf47065df1de3458a1a', 'adb_image_size': 227547, 'adb_image_width': 1024, 'caption': 'Chicken in Creamy tomato based gravy', 'contributor': 'gautam', 'cuisine': 'Indian', 'id': 4, 'location': 'NJ', 'name': 'Butter chicken', 'type': 'main dish'}, {'Recipe URL': 'https://www.tajmahal-oban.co.uk/', '_blob_index': 1, '_uniqueid': '15.7.484540', 'adb_data_source': 'IngestType.IMAGE.dishes.adb.csv', 'adb_image_height': 768, 'adb_image_id': '8', 'adb_image_sha256': '14a706e59bbbf9bd135469efb93684c69ba5c2763d94e00d8f6172537b749013', 'adb_image_size': 255347, 'adb_image_width': 1024, 'caption': 'Butter chicken, special fried rice, garlic naan, peshwari naan', 'contributor': 'gavin', 'cuisine': 'Indian', 'id': 8, 'location': 'UK', 'name': 'butter chicken with special fried rice and assorted naan breads', 'type': 'main dish'}], 'returned': 2, 'status': 0}}]

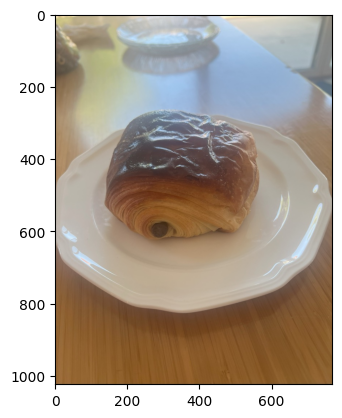
c) Find similar looking dishes to a bread
from aperturedb.CommonLibrary import create_connector, execute_query
from aperturedb.NotebookHelpers import display as nbd
from IPython.display import display
import clip
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/16", device=device)
search_tokens = clip.tokenize([f"a photo of bread on plate"]).to(device)
search_embeddings = model.encode_text(search_tokens)
query = [{
"FindDescriptor": {
"set": "ViT-B/16", # Name of descriptor set to use
"k_neighbors": 10, # How many results to return
"distances": True, # Also return distances (as _distance property)
"blobs": False, # Don't return vectors of matching descriptors
"_ref": 1, # forward reference,
"metric": "CS",
"results": {
"list": ["_uniqueid"]
}
}
}, {
"FindImage": {
"blobs": True, # Return image binary data
"is_connected_to": {
"ref": 1 # backward reference
},
"results": {
"list": ["_uniqueid"], # Return only unique ids
"group_by_source": True
}
}
}]
if device == "cuda":
search_embeddings = search_embeddings.float()
blobs = search_embeddings[0].cpu().detach().numpy().tobytes()
else:
blobs = search_embeddings[0].detach().numpy().tobytes()
client = create_connector()
result, response, blobs = execute_query(client, query, [blobs])
# Print the response
print(response)
# Check if the query was successful
if result == 0:
# Here we reorder the images based on the distances before displaying them
# based on decreasing distance from the input vector.
descriptors = response[0]["FindDescriptor"]["entities"]
images = response[1]["FindImage"]["entities"]
for d in descriptors:
bi = images[d["_uniqueid"]][0]["_blob_index"]
display(d["_distance"], bi)
nbd([blobs[bi]])
[{'FindDescriptor': {'entities': [{'_distance': 0.29368117451667786, '_uniqueid': '3.184.484840'}, {'_distance': 0.28876030445098877, '_uniqueid': '3.187.484900'}, {'_distance': 0.26952141523361206, '_uniqueid': '3.173.484620'}, {'_distance': 0.2660259008407593, '_uniqueid': '3.167.484500'}, {'_distance': 0.25563734769821167, '_uniqueid': '3.169.484540'}, {'_distance': 0.2544242739677429, '_uniqueid': '3.177.484700'}, {'_distance': 0.2532556354999542, '_uniqueid': '3.168.484520'}, {'_distance': 0.2471557855606079, '_uniqueid': '3.178.484720'}, {'_distance': 0.2463374137878418, '_uniqueid': '3.170.484560'}, {'_distance': 0.24523672461509705, '_uniqueid': '3.164.484440'}], 'returned': 10, 'status': 0}}, {'FindImage': {'blobs_start': 0, 'entities': {'3.164.484440': [{'_blob_index': 0, '_uniqueid': '15.2.484440'}], '3.167.484500': [{'_blob_index': 1, '_uniqueid': '15.5.484500'}], '3.168.484520': [{'_blob_index': 2, '_uniqueid': '15.6.484520'}], '3.169.484540': [{'_blob_index': 3, '_uniqueid': '15.7.484540'}], '3.170.484560': [{'_blob_index': 4, '_uniqueid': '15.8.484560'}], '3.173.484620': [{'_blob_index': 5, '_uniqueid': '15.11.484620'}], '3.177.484700': [{'_blob_index': 6, '_uniqueid': '15.15.484700'}], '3.178.484720': [{'_blob_index': 7, '_uniqueid': '15.16.484720'}], '3.184.484840': [{'_blob_index': 8, '_uniqueid': '15.22.484840'}], '3.187.484900': [{'_blob_index': 9, '_uniqueid': '15.25.484900'}]}, 'group_by_source': True, 'returned': 10, 'status': 0}}]
0.29368117451667786
8
0.28876030445098877
9
0.26952141523361206
5
0.2660259008407593
1
0.25563734769821167
3
0.2544242739677429
6
0.2532556354999542
2
0.2471557855606079
7
0.2463374137878418
4
0.24523672461509705
0







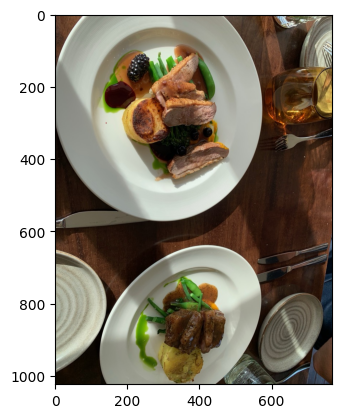

What's Next?
- Think about how to move from your current data tools to ApertureDB - learn more about the unique features and differences
- Learn to add and work with various objects in your instance using our Cookbook dataset
- Bulk load various data types