Migrate From Relational Databases
In a relational database (e.g. SQL-based), the schema is defined by the creation of tables, where each table has named columns. Some columns are “foreign keys” that form links between different rows, often in different tables. Columns have types and can have other constraints. Blobs (typically limited in size) are stored in columns.
In a multimodal database like ApertureDB, things are a little different. ApertureDB follows the property graph model for storing metadata. Let's for now defer the vector database and data management features and focus on the graph as shown in the image below and discussed in detail after.
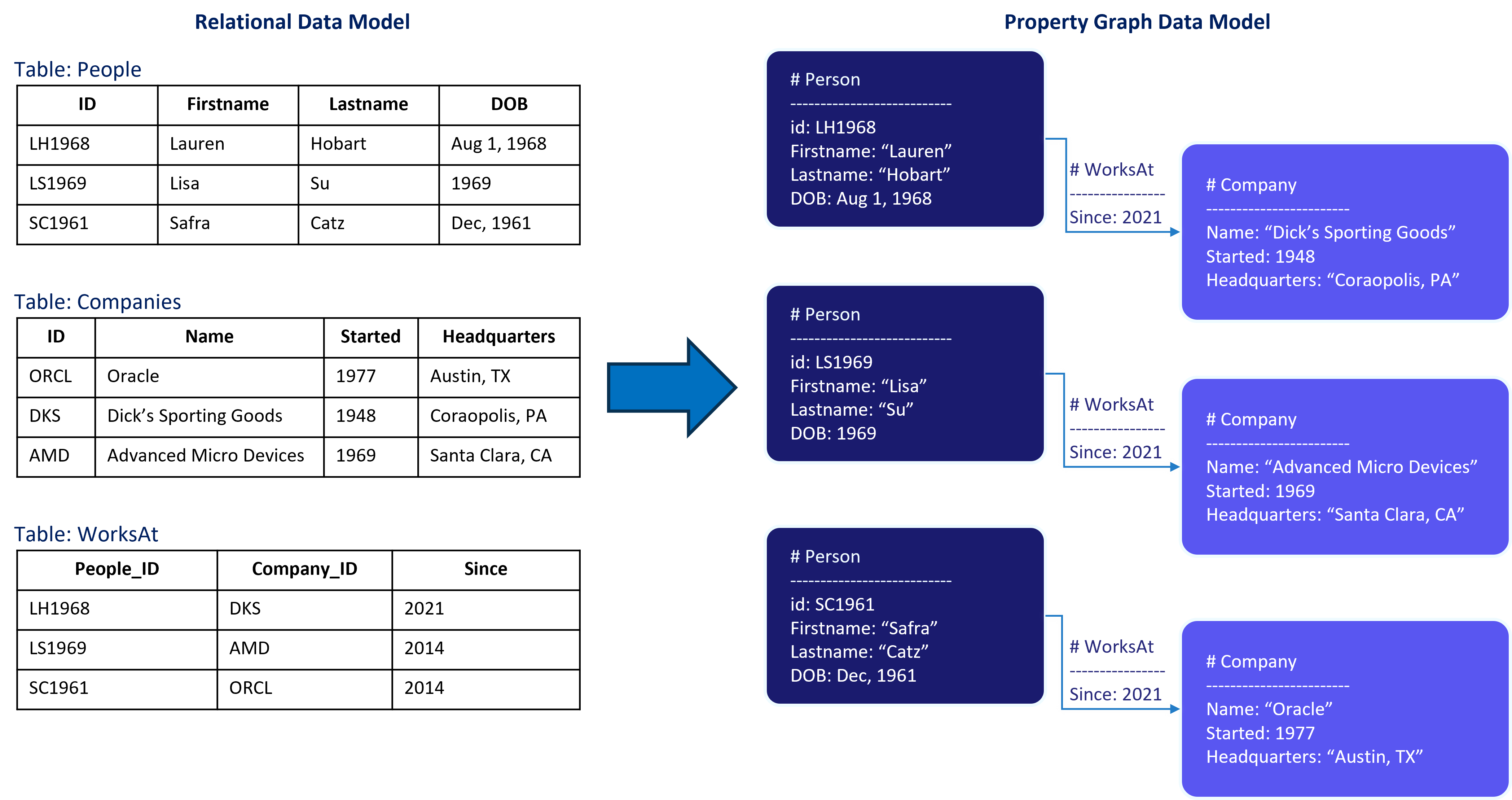
TLDR;
| Relational concept | ApertureDB equivalent | Difference |
|---|---|---|
| Tables | Each record as Object with given Class | Each row in the table becomes an ApertureDB object of the given Class |
| Attributes or columns in table | Key-value properties per object | Schema in ApertureDB is flexible and new attributes can be introduced as needed |
| Foreign keys | Connections | Connections actually have Class themselves and attributes of their own, so are as powerful as join tables |
| URLs to external sources for large objects | Native representations for Embeddings, Images, Videos, Clips, Frames, regions of interest, Blobs | Relational databases don't represent unstructured objects |
| Aggregation on basic types | Aggregation on basic types but also pre-processing of images, videos, and derived types | Aggregation is for key-value properties and augmentation for special objects |
| Explicit schema | Implicit schema with some pre-defined types like Image, Video, Descriptor etc | ApertureDB schema can evolve over time as application evolves |
| SQL as query language | JSON-based query language | ApertureDB queries need to address multiple modalities of data in one |
Classes instead of tables
Instead of tables, there are objects or nodes in the graph with different classes. For example, if you have a table with Employee information, in a relational model, there will likely be one Employees table with the various rows representing individual employees. That in ApertureDB will translate to one node in the graph per employee with a class name, for instance, "Employee". In ApertureDB, many rich media types such as videos, images, and descriptors (embeddings) have specific support and have built-in classes. Other types of object can be defined as separate entity classes. Note here that one SQL table may end up as multiple classes if the table includes multiple blob columns.
Connections instead of foreign keys
Instead of foreign keys to provide a one-way link between tables, ApertureDB has connections or relationships between various objects or nodes in the graph. This is similar to an “edge table” in SQL. Like entities, every connection has a named class.
Properties instead of columns
Both objects and connections can have metadata properties (often represented as key-value pairs) which correspond to the columns in a SQL database. The type system is simplified, e.g. “String”, “Number”, “Datetime”. Typically the client does not specify types explicitly, but they are inferred from the values given.
Special objects
Given that ApertureDB is built for multimodal AI applications, it has some specially defined objects such as "Image", "Video", "BoundingBox", "Polygon", "Clip", "Frame", "DescriptorSet" (a collection of embeddings), and "Descriptor" (embeddings), among others. There is no equivalent in relational databases for such representations.
Augmentation operations instead of client-side processing
Since relational databases don't recognize special objects, they mainly just support simple statistical operations on their columns of numbers or sorting on text. While you can do those on the metadata stored in ApertureDB, it also explicitly supports more advanced pre-processing and augmentation operations on objects like images, videos, and regions of interest (e.g. bounding boxes, clips). You can sort, embeddings by distance metrics, and perform very advanced operations like indentifying Intersection over Union for certain types of regions of interest.
Schema is implicit instead of explicit
One big difference between setting up ApertureDB and a SQL database is that in ApertureDB,
the schema is inferred. Simply by creating entities of a specific type, that class now exists.
Simply by adding named properties with specific values, that class now has typed properties.
There is no equivalent of a CREATE TABLE or UPDATE TABLE command but there are Add* or Update*
commands to introduce objects and connections.
Note that, although the schema is inferred, it is also enforced, so a client cannot add the same property to objects of the same class with different types.
The schema is also flexible in that, it is possible to easily introduce a new property in some objects or connections of a specific class at any point in time. You can also introduce new connections or remove old ones as needed.
Indexing
In a SQL database, a lot of time is spent optimizing the indexes. Many indexes are on a single column, but it is also possible to set up complex indexes across multiple columns.
In ApertureDB, we have found that most of the benefit can be obtained from single-property indexes. These can be created using:
- The CreateIndex command
- The Utils.create_entity_index() and Utils.create_connection_index methods
Connections are implicitly indexed. Descriptors have special indexing that supports ”find similar” searches.
Extracting the schema
Once an ApertureDB database has been set up, the schema can be obtained in a number of ways:
- The GetSchema command
- The Utils.get_schema() method
- The
adb utils execute summarycommand line tool that outputs a human-readable description of the schema - The
adb utils visualize-schemathat generates an image visualization of the schema, similar to what is seen in may SQL tools
Unlike a typical SQL schema, ApertureDB schema will include counts for objects of all classes and properties, and whether each property is indexed.
Query language
The ApertureDB query language is very different from SQL. It is JSON-based and is composed of a sequence of commands executed in order. Commands that find objects or connections can return a list of results, but they can also assign those results to a reference to be used by a subsequent command (to support graph traversal).
The query language is described in detail in our Query Language Reference.
Following data links
Something that relational databases don't generally allow is embedding data objects in columns. There is a possibility of storing small images, text, or JSON strings as byte strings but it's not often a recommended practice. When people are representing metadata about objects like pdfs, images, videos, or other data formats, they typically store the data object in file systems or object stores, and introduce the URLs as a column in the database. When working with ApertureDB, you no longer need to explicitly access any external storage and can store and access any objects directly through our query interface. In fact, we have further support for preprocessing and augmentation operations, as well as annotation support for images and videos. Other data types can be represented as Blob objects and accessed without any format change.