ApertureDB Ecosystem and Integrations
Database Design
ApertureDB is based on the open source VDMS (Visual Data Management System) code. It implements a client-server design. The Server handles concurrent client requests and coordinates request execution across the metadata and data components in order to return a unified response to the client.
Building Applications
ApertureDB manages the data and metadata. It can store and access this data from cloud buckets or storage managed by the ApertureDB server. ApertureDB also offers integrations with various ETL and AI tools and frameworks for creating user applications.
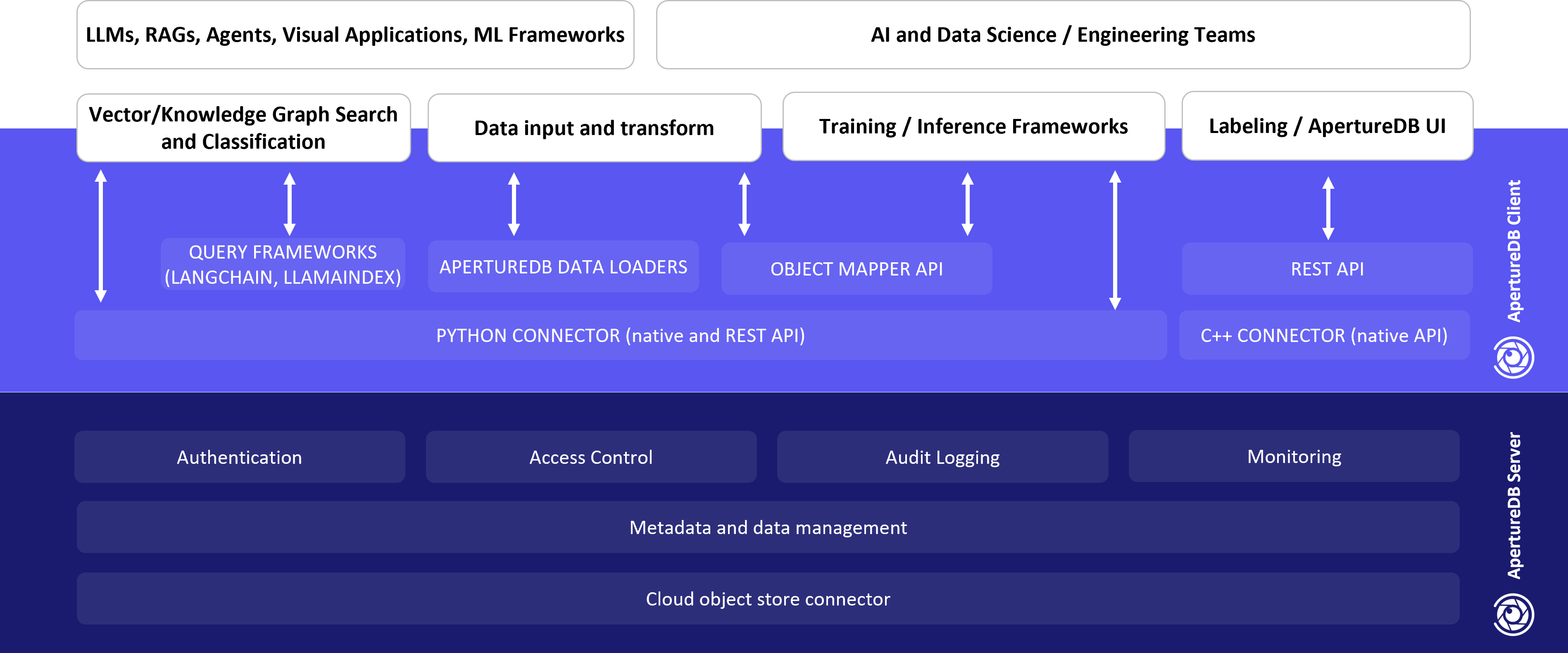
We offer both TCP and REST APIs that can easily be used by any labeling frameworks or user's in house web front ends.
In addition to our network APIs, we also provide ApertureDB client packages that can be integrated directly with with C++ or Python applications.
To ingest data into ApertureDB, we provide fast bulk data loaders. These loaders can be run periodically to refresh data via frameworks like Apache Airflow.
We also have dataset loaders for ML frameworks like PyTorch and Tensorflow where our loaders hide the complexity of fetching training or classification data in batches and users just need to specify queries to find the right data.
To support various enterprise and IT requirements, we also offer authentication, encrypted communication between clients and server, role-based access control, logging, and database monitoring.