Example Technical Use Cases
How does ApertureDB fit in an ML workflow?
Through its unified approach and user tools, ApertureDB provides seamless integration within existing and new analytics pipelines in a cloud-agnostic manner. Here are some common use cases we have seen in a classic CV / ML application. These demonstrate how ApertureDB can benefit various types of user personas from data engineers, platform teams, data scientists, to data science managers across different application domains. For business or domain specific use cases, please refer to our website.
Unified Visual Data and Metadata Management
The primary use case for ApertureDB is as a unified repository to find and work with images, videos, feature vectors (embeddings), and metadata. It significantly boosts data science teams’ productivity and collaboration. ApertureDB simplifies infrastructure configuration as a single database which also makes data lifecycle management straightforward for data engineers who rely on ApertureDB to keep metadata and data consistent.
Metadata-based Filtering and Search
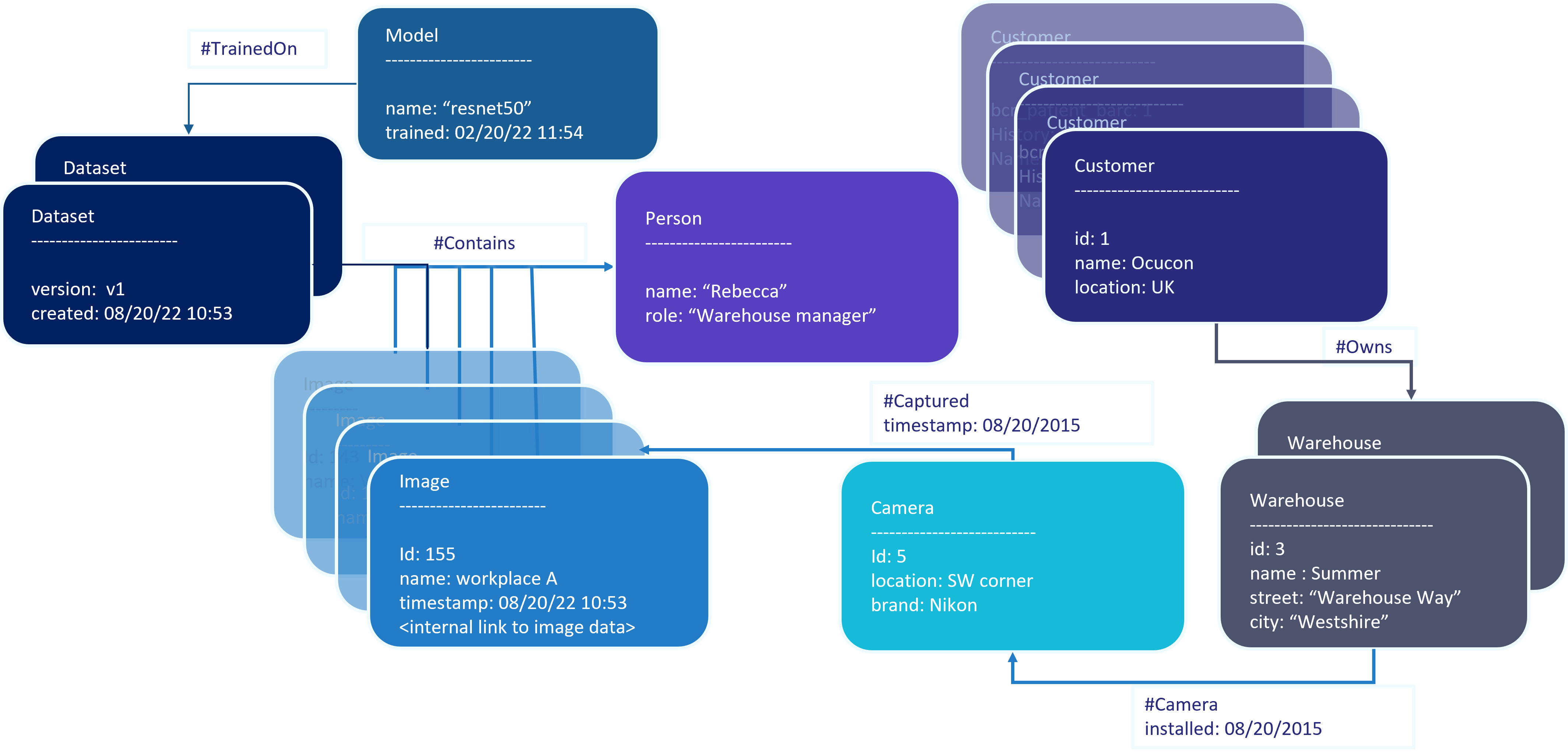
The metadata graph in ApertureDB contains entities that represent Images, Videos, Embeddings, and any generic Blobs that can be connected through named relationships to each other and the rest of the user-defined application metadata (as shown in the example graph above). Each of the entities and relationships can have any number of key-value properties that can be used for metadata based querying or filtering to find subsets of images, videos, or embeddings. Because of the graph representation, it is possible to connect any of these entities together and track origin or lineage that can then be queried using our API. This capability enables data scientists to quickly and easily connect images of a similar type across various classes to identify associations and patterns.
Annotation (Label) Management
ApertureDB supports bounding boxes for labeling or annotation-based searches as part of the metadata. Our REST API allows our users to connect with labeling front-ends and store updated labels back into ApertureDB. ApertureDB web frontend allow users to add, display as well as edit labels and bounding boxes overlaid on images.
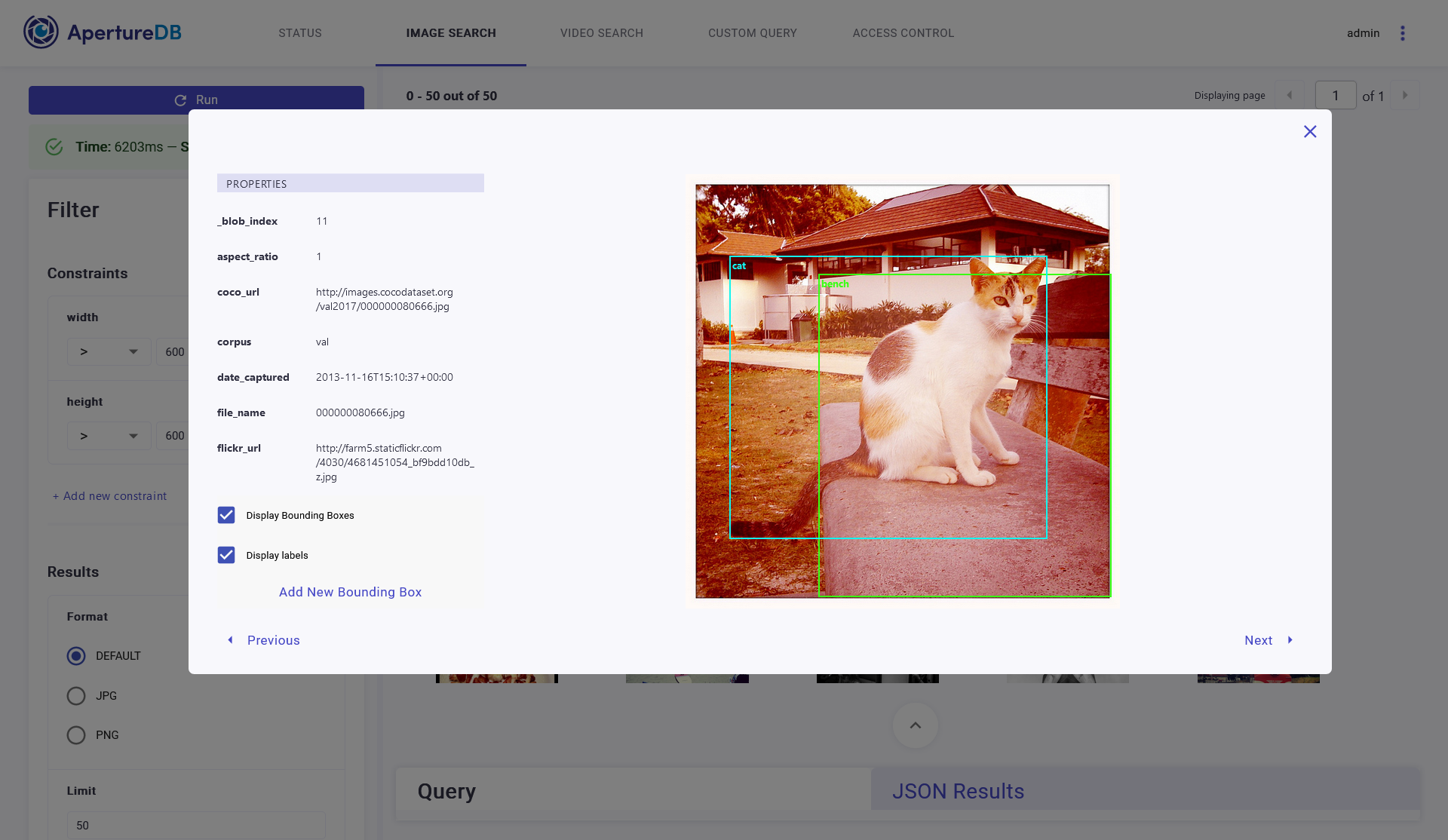
Our users are currently using ApertureDB to manage labels associated with their images. This gives them one source of truth that refers to both, images / frames and their corresponding annotations, which can then be used to search and create datasets easily. They no longer have to organize folders with annotation labels and put images / frames in those folders to create training or classification datasets. They can also avoid having to read through all the annotations to find the ones they need. The annotations in ApertureDB can be extended to contain not just labels and coordinates, but also any other information like source of annotations, the model that helped label (or auto tag), and others.
ApertureDB supports both bounding boxes and polygon shaped annotations and operations like intersection over union (IoU) for any of these annotations. ApertureDB also supports segmentation masks.
Dataset Preparation During ML (Re)training / Classification
We have dataset loaders for ML frameworks like PyTorch where our loaders remove the complexity of retrieving the right datasets to support training or classification of data in batches. Users only need to specify queries to find the right data. All the user needs to specify is a query that filters the relevant dataset. This query can in fact specify pre-processing and augmentation operations like resize, rotate, which ApertureDB then applies on-the-fly.
It is already easy to store Datasets as entities in the ApertureDB metadata graph and map them to different images / annotations. Updating (evolving) metadata schema is easy by design.
K-NN Similarity Search for Visual Search or Recommendations
ApertureDB offers indexing of n-dimensional feature vectors. Our API also supports classification of new feature vectors and K near neighbor searches. In addition we enable users to select the engine and distance metrics at runtime when doing similarity searches. The feature vectors can be connected to images, frames, or bounding boxes to allow finding the related images once you find similar feature vectors. Our users use this capability to build visual recommendation engines and to find the closest matches within images or frames.
Data Filtering and Visualization / Visual Debugging
In addition to our JSON and Python object based query capabilities to filter data by metadata, our web frontend also allows users to specify metadata constraints to find relevant images. This is an easy way to get started and also examine your dataset visually.
Many of our users also prefer to use the web frontend as a way to easily navigate through datasets, search for any anomalies, modify labels as needed, and experiment with custom queries.
Comparing Accuracy Achieved by Various Models
As mentioned earlier, ApertureDB metadata is stored as a graph that can be extended with any user-defined entities and their attributes. This allows our users to create entities representing ML artifacts like “Model”, connect them to the data that was used to train them, use these to classify new data, and attach the accuracy values seen when classifying. This can enable searches like “find images classified by Model X where accuracy is > 0.9”.