Distributed ApertureDB
In this section, we describe the core components that help us manage metadata, embeddings, and data itself. We scale these components so ApertureDB can scale linearly for reads, handle very large datasets and provide much higher throughput, reliability, and performance for data and performance intensive multimodal applications. The following figure shows the various components that make it possible to scale ApertureDB horizontally.
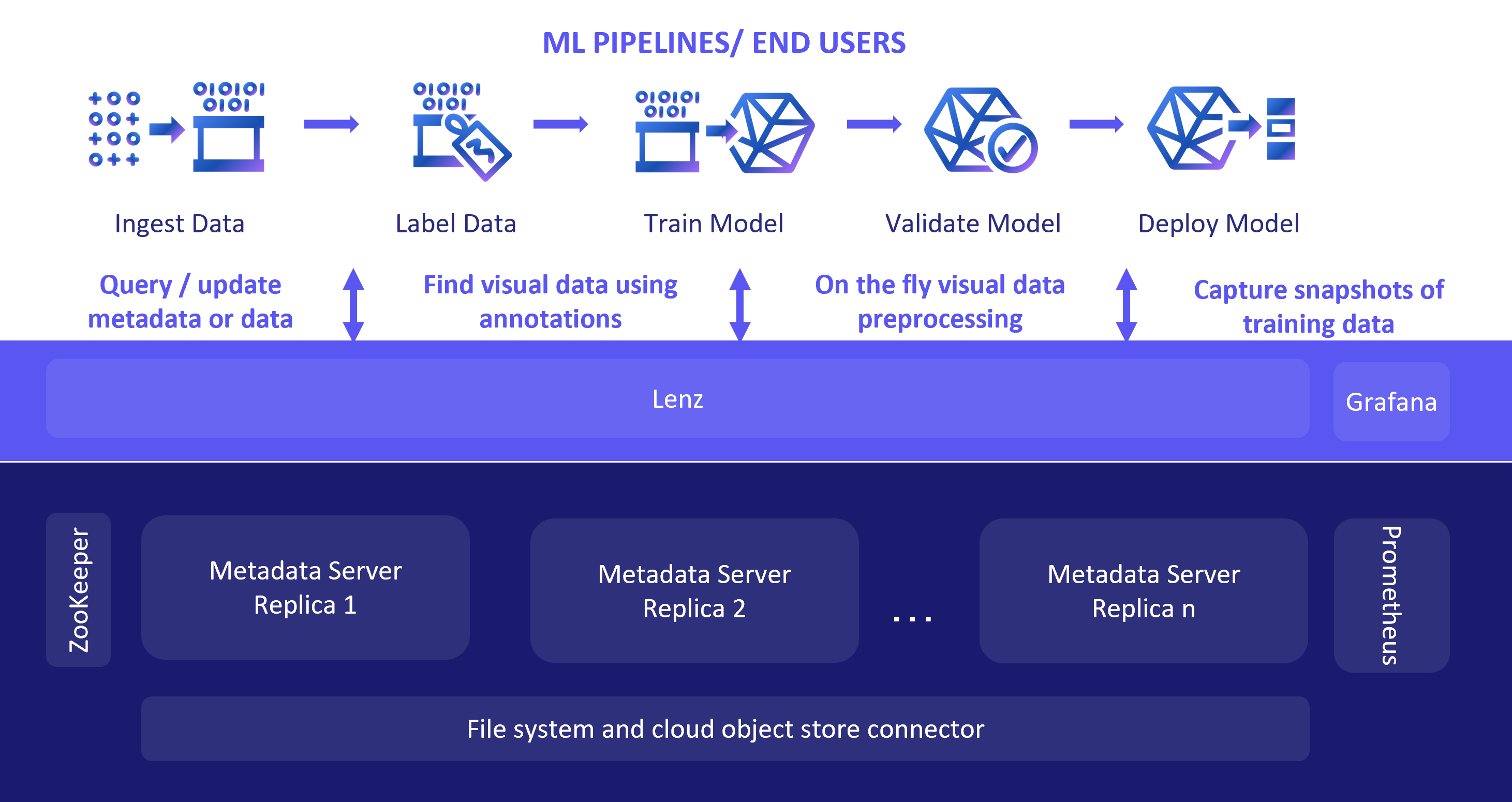
ZooKeeper
Apache ZooKeeper is used for distributed coordination between the metadata servers. We use Zookeeper for service discovery, acquiring global locks and committing global transactions.
Lenz
Lenz is the front end load balancer. It accepts both TCP/IP and HTTP connections and forwards the requests to one of the metadata servers, usually to the lightly loaded one. Lenz discovers the metadata servers from ZooKeeper.
Metadata Servers
ApertureDB consists of an internal graph-based metadata store that is based on the key value store LMDB. The keys are a combination of entity type, id (a unique integer identifier) and the value type. The different value types are the node/edge value, and various property types i.e, string, number, bool and date.
Write transactions
An edit consists of the triplet (operation, key, value). The operation can be an update, add or delete. The change is applied to the local key value store and added to a changelog file. The commit consists of persisting the changelog file to stable storage and updating ZooKeeper with the transaction commit and the corresponding changelog file path.
A Write transaction consists of acquiring a global lock from ZooKeeper. The lock is associated with an automatically incremented global id. The global id is used as the transaction id for the write transaction. After acquiring a global lock the transaction makes lock edits and all the edits are appended to the changelog file. Before commit, the changelog file is uploaded to a stable store like S3 or Google Storage. The path to the changelog file is stored in ZooKeeper and is associated with the global transaction id. Storing the file path in zookeeper marks the transaction as committed and makes the changes available to the other metadata instances.
The other replicas are informed about the transaction (via ZooKeeper) and they update their local information.
Periodically a snapshot of the database is copied to the stable storage, called the checkpoint. Whenever a new replica starts, it uses the latest checkpoint and applies all the new changelogs.
Read transactions
Read queries do not require a ZooKeeper lock. The metadata server fetches the new write transactions executed by other metadata servers. The fetch includes the corresponding changelog file. The changes captured in the changelogs are applied to the local database and then the read query is executed.
Working with ZooKeeper
All the metadata servers broadcast their URLs by registering their address in ZooKeeper.
Monitoring with Prometheus and Grafana
Prometheus ambassador is a sidecar application that queries the metrics from the metadata servers and makes it available to Prometheus. The Grafana dashboards for monitoring all the replicas and activities are populated by querying Prometheus.
Logging
Metadata servers write their logs to the filesystem using glog. The system uses Graphana’s Loki to present and query the logs. Promtail scraps the log files to upload them to Loki.