Define Metadata Schema
The ApertureDB Query Language provides a way to add application-specific entities, along with their relationship (or connection) with each other. It is important to remark that no schema declaration is needed upfront.
The schema is application-dependent, and can evolve over time. For example, if we are building a visual pipeline for a retail store that will analyze customer behavior, one could imagine entities like Customer, Object, Department, and Employee. In addition, there could also be more conceptual entities like a Visit to indicate a customer's visit to the store, a feature vector representing a customer's features to enable in person reID, the actual video snippets captured by cameras, and so on. Each of these entities could, in turn, have their own properties, either known at the start of the application or added over time. For example, a department could have a name, information about its physical location in the store, camera(s) installed overhead, and other things like description. An object could have an RFID tag associated with it, a type indicating whether it is a ketchup bottle or towel and so on.
ApertureDB implements a property graph data model. Think of entities like tables in a relational database world and relationships among them as tables with foreign key associations. The key-value properties in each entity or relationship are similar to column names and their values in a relational table. However, the graph model makes it very easy to evolve the schema as the application evolves and allows us to support complex keyword based as well as graph traversal based searches.
By default, we already introduce entities in the graph representing all the native objects like images and videos (all objects). We also create some default connections such as a connection between a Descriptor and DescriptorSet.
Here is an example of what a schema would conceptually look like in a "Analytics for Retail" use case:
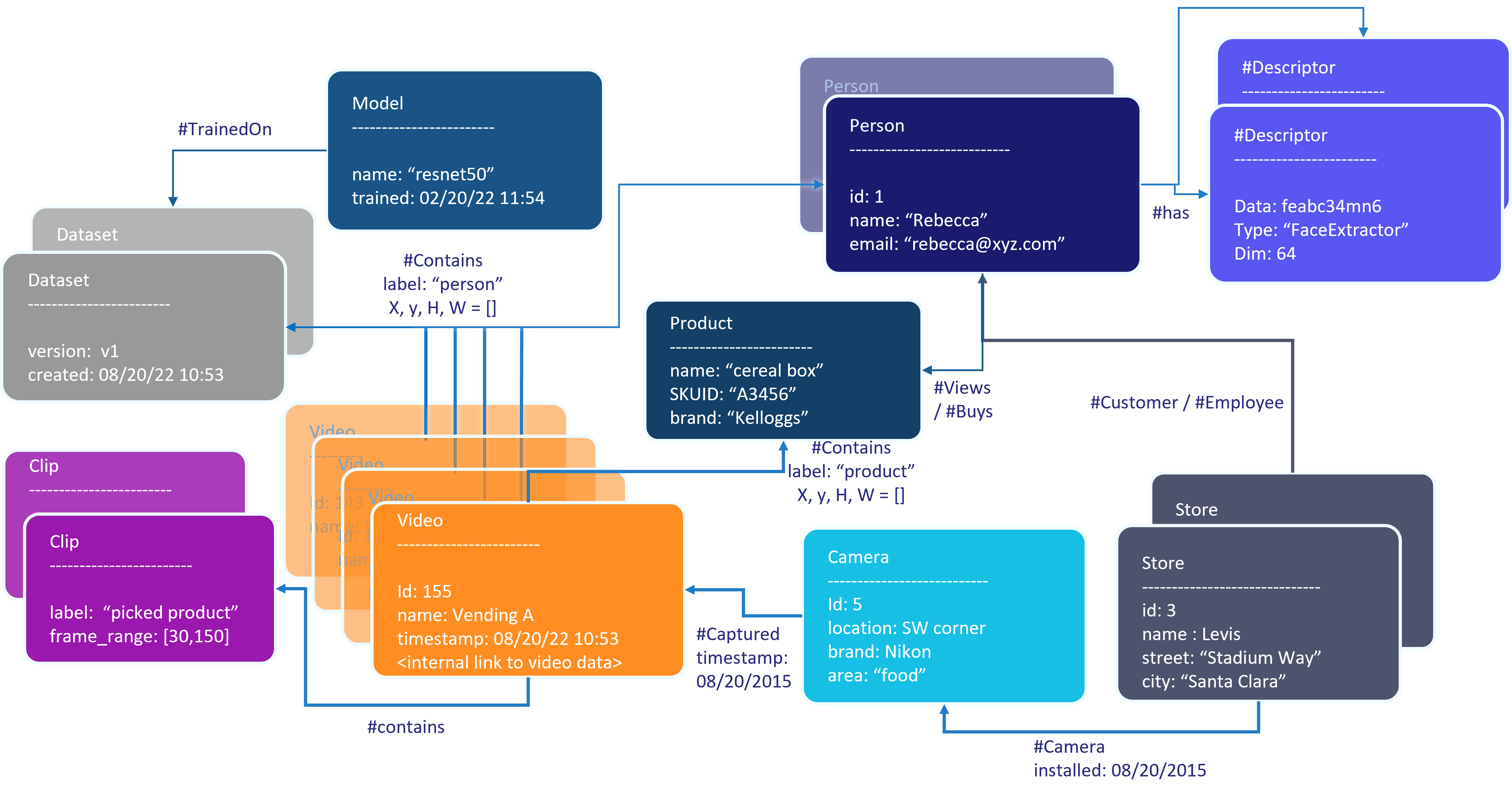
As the application evolves, we could introduce new information in this metadata like color of a product, or the number of times it was picked up.
Here is another example of a schema in case of a visual or industrial inspection application.
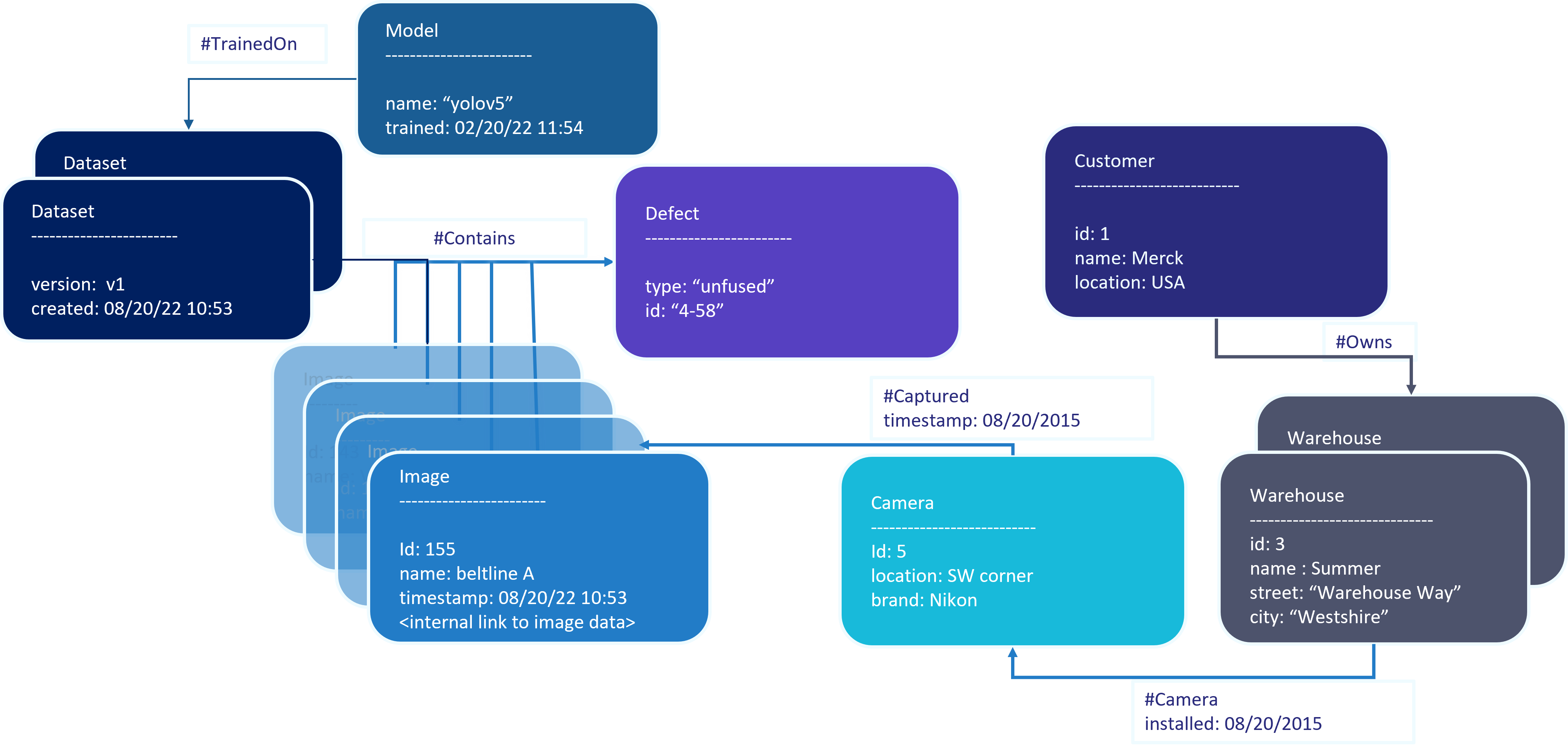
Typically we work with our users to get them started with a schema based on the queries and data that will be supported by ApertureDB.
Index for Performance
Like a lot of other databases, ApertureDB uses indexes to speed up query execution. Indexes should be defined on any key-value properties for entities or connections that will be used for querying. These indexes can be defined using our JSON API at the time of database creation so that all new entities and connections get indexed when they are added, or indexes can be added or removed later as the application evolves.